In-Context Generalization to New Tasks From Unlabeled Observation Data
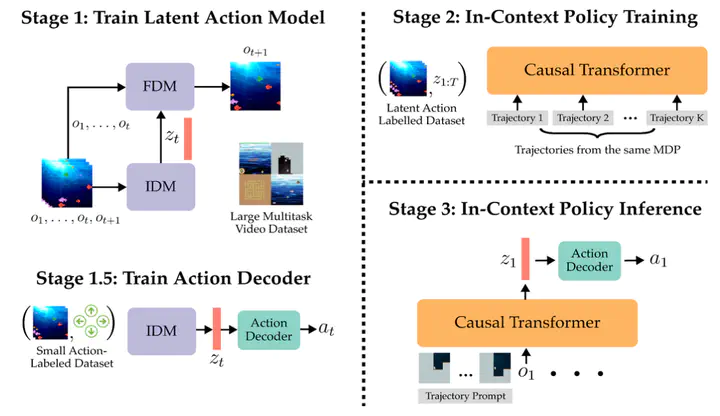 Prompt-DTLA Pipeline
Prompt-DTLA PipelineAbstract
Large pretrained models in natural language processing and computer vision have achieved impressive capabilities by training on vast internet-scale corpora. However, for sequential decision-making agents, such as robots and other autonomous systems, it is difficult and expensive to collect large amounts of expert demonstrations hindering their ability to learn new tasks efficiently. Leveraging unannotated internet videos as a resource, we propose an approach to train a generalist agent capable of few-shot adaptation to new tasks without fine-tuning. Our method, Prompt-DTLA, learns a latent action model to annotate video sequences with latent actions that enables training an in-context causal transformer policy on these annotated trajectories. At inference, the agent can generalize to new, unseen tasks using few-shot in-context demonstrations without additional fine-tuning. Prompt-DTLA offers a potential solution for scaling robot learning with free, internet-scale data rather than expensive human demonstrations, enabling generalist agents to learn new tasks from unlabelled data sources.